|
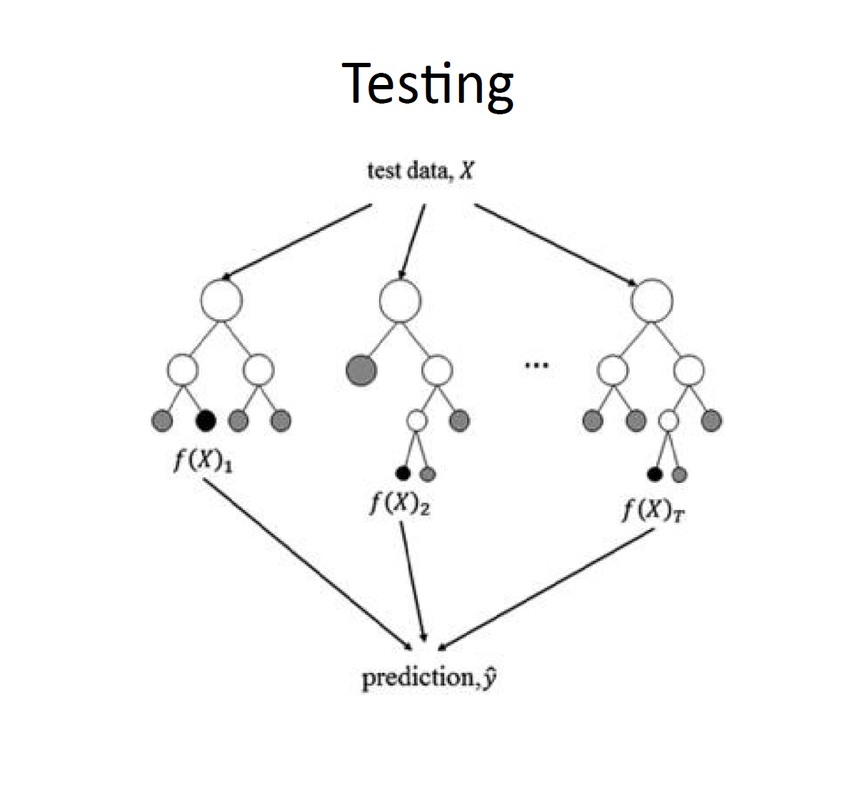
Ravina More conducted a session on 16th October, 2018 on Random Forest Classifiers.  Ravina More during the session Her talk started off with the basics of writing a code to train your model. The most important part is choosing an appropriate algorithm to train the model. Depending upon the need of our model we chose an algorithm which then shapes our entire model. In total there are four different methods available to choose - Classification, Regression, Clustering method and Dimensionality reduction. If your model is trying to predict the category in which a given sample will fall into, either Clustering or Classification algorithms are used. Classification is possible only when labeled data is available. If non labeled data is available then clustering method is adopted. However if your model is trying to predict a certain value and not a category, Regression or Dimensionality Reduction algorithms might be better suited for training your model . Regression is the method we use for prediction purpose. And if we want to create an apt data set out of available huge data then we use Dimensionality reduction algorithms. It is also used to identify and eliminate redundancies.  Choosing your learning algorithm In this session our main focus was Classification algorithms. Random forest classifier is a classification algorithm. Examples that fall under this category are Email Filtering, Face recognition etc. An example was then explained for us to get proper idea about how exactly the algorithm works. The example was – To Play Golf or Not. The features in the data set were – outlook, temperature, humidity, wind. The output that we need is “yes” or “no” to play. Among these variables it is important for the programmer to decide which variable is the deciding factor for our output. But to figure this out going through entire data is not feasible. Instead we use decision trees to help us visualize our features and relate them to the required output. J48 or CART algorithms can be used to generate this tree. Consider an example of a room full of bulbs. If we light up entire room with a single large bulb, room will be bright but, if we light the room with small equal bulbs and spread these bulbs over entire room, room will be more properly lit.  Decision Tree to decide whether to play golf or not In the same way, when our data set is very large, one tree cannot suffice. Additionally, one tree is fast but not as accurate as multiple trees. When a big data set is being split into multiple trees we are using RANDOM FOREST CLASSIFIER algorithm. The important thing is that we need to make sure that all trees are not learning the same data. In Random Forest Classifiers, we train multiple trees on features that are a subset of all the features in the training data set. The decision boundaries of these boundaries are then averaged out to get a final output as shown below.
Now to determine how many trees should be available for a data set, it is recommended that
 IRIS Data Set visualized in Weka  Results of classifying with Random Forest Classifier Random forest classifier is only to be used when the available data set is huge. If data set is not very huge the accuracy by Random forest classifier is less than accuracy by a normal single tree. This happens due because number of combinations taken up for the tree overlap and the splitting of data overlaps due to which result starts to become irrelevant. It is important that our data set only has relevant information otherwise the accuracy will never be at its maximum. So data set should be very accurate. Additionally, Random forest classifier cannot over fit the data set with respect to number of trees. When a particular set of trees has given us maximum accuracy, and we wish to save that set of trees, a feature called “seed” is used to maintain that same number of trees for same outcome/result. Ravina then showed us a Jupyter Notebook with implementation of a Random Forest Classifier, which can be found here. She encouraged us to go through it and try to understand how to implement this algorithm for our own data sets. The session was concluded with questions from the students and a game of Kahoot. Written by Jui Bangali.
0 Comments
Before we delve into how we can apply the concept of Machine Learning in an Intrusion Detection system we need to understand what an IDS really is and how it works. What is an IDS? An intrusion detection system (IDS) is a type of security software designed to automatically alert the administrators when someone or something is trying to compromise the information of your system through malicious activities or through security policy violations. How it works: An IDS basically works by monitoring the system’s activities by examining all the vulnerabilities for the system, the integrity of the files present and conducts an analysis consisting of patterns of attacks that are already known to it. It also automatically monitors the Internet to search for any of the latest threats which could result in a future attack to the system. Intrusion detection is based on the assumption that the behaviour of the intruder differs from that of a legitimate user in ways that can be quantified. Of course, we cannot expect that there will be a crisp, exact distinction between an attack by an intruder and the normal use of resources by an authorised user. Rather, we must expect that that there will be some overlap. 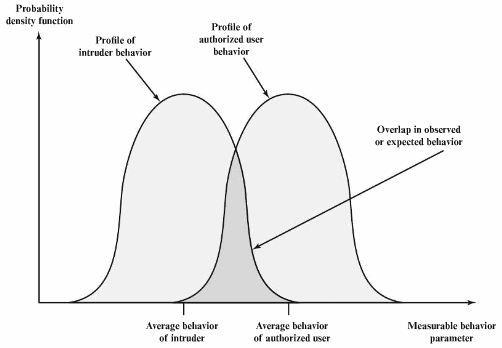 Profiles of Behavior of Intruders and Authorized Users There are multiple approaches to intrusion detection:
Evaluating ML for an IDS: With a machine learning algorithm, performance can be measured using the F-score. However, for intrusion detection systems, this is not quite enough. The F-score assumes that recall and precision have the same importance which is not necessarily the case when evaluating intrusion detection systems. A false positive occurs when a sample is actually normal but is classified as an intrusion similarly a false negative occurs when a sample is actually an intrusion but is classified as normal. A false negative is terrible, since it means that the intrusion was not detected in the first place. But most IDS’s are used in a layered approach. This means that if one layer does not detect an Intrusion, another layer might be able to detect it. The layered approach could also work in a slightly different manner for example the first layer could try and detect as many anomalies as possible by it and then pass the data for which the anomalies have been detected to other layers. This approach means that a low recall is not bad. The scoring used for the IDS using machine learning algorithms is dependent on how the IDS is going to be used. A sophisticated attacker can bypass these techniques, so the need for more intelligent intrusion detection is increasing by the day. Researchers are attempting to apply machine learning techniques to this area of cybersecurity. The foundation of any intelligent IDS is a robust data set to provide examples from which the computer can learn. Today, however, very little security data is publicly available. An excellent example of this is given by Mutaz Alsallal who is an MSS SIEM Analyst with IBM in his article which is quite the read since he has provided a working example of how he proposes using machine learning to improve the IDS. For further understanding on the subject some useful materials are listed below: 1. Snort is a free and open source network intrusion prevention system (NIPS) and network intrusion detection system (NIDS) and used all around the world. Snort’s open source network-based intrusion detection system (NIDS) has the ability to perform real-time traffic analysis and packet logging on Internet Protocol (IP) networks. Snort performs protocol analysis, content searching, and matching. These basic services have many purposes including application-aware triggered quality of service, to de-prioritize bulk traffic when latency-sensitive applications are in use. Snort can be configured in three main modes: sniffer, packet logger, and network intrusion detection. In sniffer mode, the program will read network packets and display them on the console. In packet logger mode, the program will record packets to the disk. In intrusion detection mode, the program will monitor network traffic and analyse it against a rule set defined by the user. The program will then perform a specific action based on what has been identified. 2. When Google’s DeepMind won against one of the best modern Go champions, is used multiple AI approaches and exposed gaps in some individual strategies. This shed light on the utility in combining approaches to AI for individual problems, data security being one of these problem areas where multiple AI approaches are being used to make our information safer. Dr. Sal Stolfo a professor at Columbia in Computer Science who is now also the CEO of Allure Security, with a focus on engineering network intrusion detection solutions using AI applications talks about the various styles of AI and statistical methods that have been and are being used to detect malicious activity, as well as how he believes the future of security is going to have to adapt as increasing amounts of data become available. This is a podcast where he talks about the various styles of AI and statical methods that have been and are being used to detect malicious activity. 3. Another excellent paper which goes into the depths of how we can implement machine learning techniques in an IDS is https://arxiv.org/pdf/1312.2177.pdf Bibliography: Chapter 22. Intrusion Detection from the book Cryptography And Network Security – By William Stallings https://irjet.net/archives/V4/i12/IRJET-V4I12314.pdf Written by Anuya Joshi. |