
|
What is meant by Artificial Intelligence? So, Artificial Intelligence is nothing but the intelligence shown by machines or simply when machine or a computer program is able to think and respond like human or even better than human. Is it possible to have robots superior to human, taking decisions on their own? You might have watched this in many Hollywood movies, but apart from that it is also possible in real life with the help of AI. There are many examples in front of us like Petman, NAO, ATLAS, etc. and very special AI miracle: SOPHIA. Sophia is a humanoid robot developed by company Hanson Robotics. Sophia was activated on April 19, 2015 and made her first public appearance in March 2016 in Texas, United States. It’s creator, David Hanson is founder and CEO of Hanson Robotics. Although before Sophia, many humanoid robots were created but Sophia is special as it is the first ever robot to receive citizenship. She received citizenship of Suadi Arabia in October 2017. Other humanoid robots also can interact with human tools and environment, but Sophia along with this can also show more than 50 facial expressions which makes her special and different from other robots. Her physical appearance is another example of what some see as a traditional representation of conventionally attractive, submissive-by-design female robots. Have a look at video clip on Sophia here. She can speak, interact like normal human and can tell a joke. She can follow faces, sustain eye contact, and recognize individuals. She is able to process speech and have conversations, functional legs and the ability to walk and also some social skills. She has given many interviews and visited TV shows. She was even there at IIT Bombay’s Techfest 2017 interacting with such a big crowd of almost 3000 people over there.  Sophia at IITB Watch Sophia at IITB Inside Sophia: Basically her functioning is based on AI. It makes uses of a wide number of AI methods. There’s face tracking, emotion recognition, and robotic movements generated by deep neural networks. And although most of Sophia’s dialogue comes from a simple decision tree (the same tech used by chatbots; when you say X, it replies Y), what it says is integrated with these other inputs in a unique fashion. Her creator David Hanson said that an AI Developer have to think like parent and treat his model as child, whatever we are going to give to model will reflect in its behavior. Hanson said "That's the formula for safe superintelligence". From a software point of view, ”Sophia is like a platform”. Ben Goertzel, chief scientist at Hanson Robotics said, "You can run a lot of different software programs on that very same robot".  Sophia, the 'AI Miracle'
Cameras within Sophia's eyes combined with computer algorithms allow her to see. According to the manufacturer, Sophia uses AI, visual data processing and facial recognition. Sophia also imitates human gestures and facial expressions. Sophia uses voice recognition technology which helps her to communicate with ease.Program contains pre-written answers for some specific questions , if question or phrase other than this comes then information is sent to cloud networks and then response is generated. e.g. if asked to her “is the car red or black?”, her cameras will capture image of it, process it and generate response. Her robotic movements generated by deep neural networks and Sophia’s dialogue is generated via decision tree. David Hanson has said that Sophia would ultimately be a good fit to serve in healthcare, customer service, therapy and education. Sophia runs on artificially intelligent software that is constantly being trained in the lab, so her conversations are likely to get faster and she should answer increasingly complex questions with more accuracy. Controversies About Sophia: Even though Sophia has all above best features, she also has some drawbacks as sometimes her response seems like reading out Wikipedia, sometimes she answers late and sometimes she answers wrong or her statements are contradictory. Many experts in AI field are disappointed by Sophia’s overstated representation. Apart from that, about giving citizenship to robot by Saudi who denies equal rights to women is another controversy. But we should accept that even though she has some drawbacks or failures, she is best example of AGI (Artificial general intelligence) till date or just we can say the AI MIRACLE. Written by Shivani Joshi.
0 Comments
Let us understand what are chatbots? Chatbots are software agents which are capable to have conversation with the end user. The user interacts with the chatbots by typing in the conversation or simply by using voice depending on the type of conversation like Apple's Virtual Assistant, Siri or Amazon's Alexa or Microsoft’s Cortana interact via voice rather than text. Chatbots have become extraordinary in recent years due to advancements in Machine Learning ,Natural Language Processing.  Natural Language Processing What are Chatbots used for?
How Do Chatbots Work? At the heart of chatbot technology lies natural language processing or NLP, the same technology that forms the basis of the voice recognition systems used by virtual assistants such as Google Now, Apple’s Siri, and Microsoft’s Cortana. Chatbots actually processes the text given to them and then according to a complex series of algorithms it understands , interprets and identifies what the user is saying, infers what they mean and/or want, and then determine a series of appropriate responses based on this input information.  Flow in Chatbots Chatbots are becoming human nowadays and offering a remarkably authentic conversational experience, in the sense that it is difficult to determine whether the agent is a bot or a human being. Chatbot technology is distinctly different from natural language processing technology, without constant developments or researches in NLP, chatbots remain at the mercy of algorithms. Chatbots have to struggle to parse human speech or voice ,despite many considerable limitations, chatbots are becoming increasingly sophisticated, responsive, and more “natural.” Now that we’ve established what chatbots are and how they work, let’s get to the examples.
 'Evil' AI The dark side of Chatbots
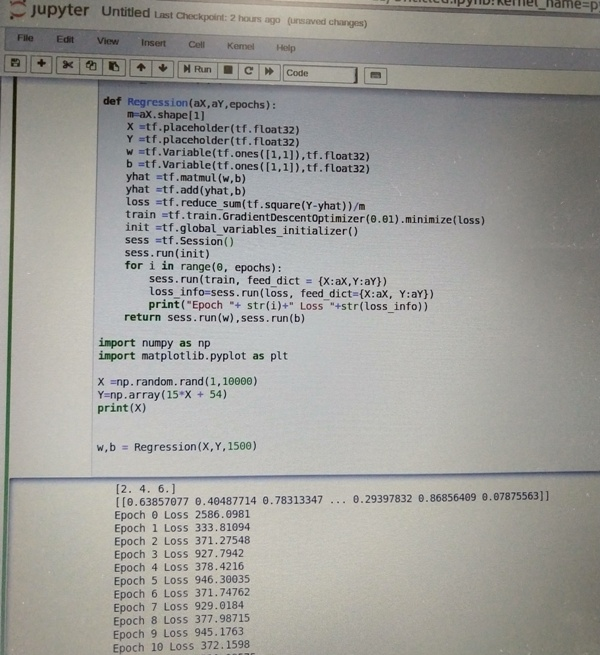
Bibliography and further readings: https://chatbotsmagazine.com/the-complete-beginner-s-guide-to-chatbots-8280b7b906ca https://www.google.co.in/amp/s/www.computerworlduk.com/galleries/it-vendors/innovative-ways-companies-are-using-ibm-watson-3585847/%3famp https://www.chatbots.org Written by Bhavana Mache. One of our volunteers, Jui Bangali, recently attended an MLCC (Machine Learning Crash Course) at PICT on 8th September, 2018 held by Nikita Kotak, Rucha Tambe and Daksh Pokar. The session started off with the prime and most popular question – What is the difference between machine Language and AI? The Answer to this is Machine language is basically a subset of AI. The scope of AI is much broader than machine language. To explain with an example – Machine Language is simply predicting an output based upon the given data whereas AI involves machines that can perform tasks that are characteristics of human intelligence. Some basic terminologies are introduced in further session. Label is the keyword used for the output that we desire at the end of a program. Model gives us the output(y) after we give it an input(x) and train it. Example is a keyword for the program that we will be performing. It has two categories in it – LABELED and NOT LABELED. Labeled one is the example trained with features and not labeled one is where no features are used to train. The two main and basic categories for discriminating programs are Regression or Classification. Regression is the kind of program where we will be getting a continuous output. Classification is the program where we will get the output in the form of either yes or no. An example of linear regression is further explained with a data set of “Chirps of crickets”. Basic statement of this example is to predict the temperature depending upon the chirps of crickets per minute. Here our “y” is the temperature to be predicted, “x” is the chirps per minute, “m (slope or is also known as the weight)” gives us the solution as how data set fits perfectly, “c (y-intercept) also known as bias)” shows us whether our line passes through origin or not, that is shows us if machine gives the any output at zero or not. When there are more than one input to be given, each input has different weight (feature). One of the most important factor to be counted while writing any example of prediction is LOSS. It is the difference between prediction and the original expected answer from the machine. We can find this loss by using a simple function. The whole point of calculating this loss is to reduce it further by training the model accordingly. Loss for each ‘example’: (observation - prediction(x))^2 = (y - y')^2 Link to a small demo of calculation of loss is provided below: https://developers.google.com/machine-learning/crash-course/descending-into-ml/check-your-understanding Another important aspect of reduction in loss is using Gradient Descent Algorithm. To read more about the concept and mathematics behind this algorithm refer to the following link. https://spin.atomicobject.com/2014/06/24/gradient-descent-linear-regression/ Further in the session a demo of how we write the code using Tensorflow in Google Collab or Jupiter notebook was shown. A little background on PYTHON is required for thus particular session. In Jupiter Notebook we import Tensorflow as an object “tf”. Using this object further we use different functions. Example of a simple code of addition of two matrices is being shown below.  Some basic functions and their descriptions include:
 The session was deeply informative and a great introduction to practical ML. We highly encourage everyone to attend sessions like this and familiarize yourself with ML, be that through Coursera or workshops. Whatever works for you! Written by Jui Bangali. What is solid state storage? We first begin by looking at what Solid State electronics imply. Earlier notions of solid-state devices were centered around devices which used semiconductors to conduct electric current instead of vacuum tubes. These days however, solid state storage refers to a device of non-moving parts which uses transistors, more accurately, integrated chips (millions of transistors connected to function on a chip) to function. Solid state storage comes in three main form factors where form factor refers to the physical arrangement/configuration of solid state media: 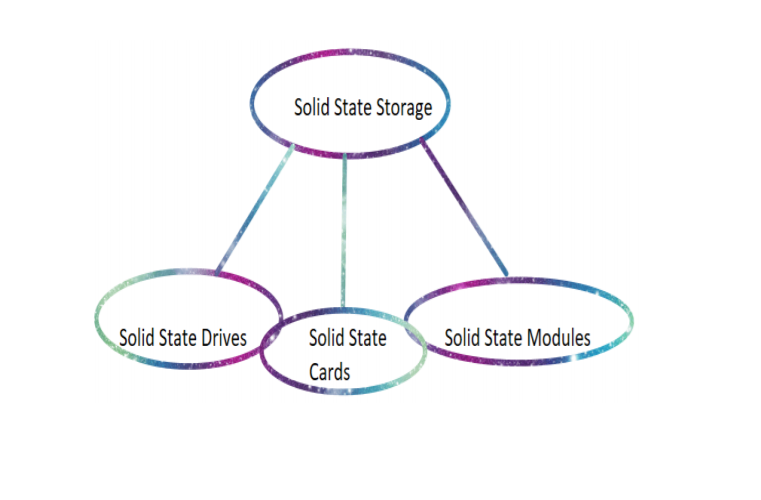 The given three main form factors are decided by the Solid State Storage Initiative. Solid State Drives are non-volatile (not needing electric supply to function (ref. to a memory storage device)) memory storage devices which uses NAND flash memory to store data. In recent times, they have been used in place of HDDs( Hard Disk Drives) in computers, which considerably improves the speed of operation of the computer. This happens because HDDs use a mechanical arm to read and write data magnetically by magnetizing or demagnetizing sectors of an aluminium or platinum plate contained within, which due to mechanical constraints, causes lag called latency in the functioning of the system. On the other hand, SSDs store their data in the substrate, using interconnected ICs which is why it is easily read and they function faster. The SSDs are made non-volatile using Floating Gate Transistors (FGRs), which holds the electrical charge.  The above picture clearly defines the physical differences between an HDD and an SSD. Recently, manufacturers have chosen to use SSDs instead of HDDs in computers. Users may also choose to upgrade their laptops by replacing the old HDDs with an SSD. Learn how to do it yourself here. This is possible because SSDs further come in form factors which are similar to those found for HDDs, say a 2.5 inch drive. Other form factors of solid state storage like solid state cards and solid state modules are used extensively as secondary/external storage devices, in place of CD-ROM or Floppy disks. They are increasingly being used as cache memory and for primary storage, on the enterprise level (RAM and DRAM are volatile solid state storage devices). Furthermore, the USB drive (flash drive) is looked upon as being a consumer based solid state device itself.  Storage terms The storage terms associated with SSSs are:
Perform/Erase cycles and the bane of Solid State Storage Different types of SSS devices have varying limitations on the number of write cycles which they can go through. Flash SSS devices, for example, have a finite number of write/erase cycles which limits their usage to that number. Write/erase cycles, also called program/erase cycles are a sequence of events in which data is written to solid-state NAND flash memory cell (such as the type found in a so-called flash or thumb drive), then erased, and then rewritten. The program/erase cycles of an SSD can determine its endurance because every new operation (write/erase) damages that portion of the SSD a little. This is because writing new data on an SSD requires the deletion of old data from that point (which is not the case with HDDs as they simply change the magnetization of a given sector). The memory cells (from SLC/MLC/eMLC) stores data in pages, i.e. a group of cells= a page. A group of such pages makes up a block. In flash-type storage, writing may be done on pages but deletion occurs block-wise. That is to say, for one to delete written data, the whole block of cells must be deleted. So to delete one page of unwanted data, one must first copy all waned pages from a block onto another block and then delete the previous block containing the single unwanted page. This process is clearly a waste of space and energy, as each erase process causes a high electric charge to hit the given flash cells, causing gradual damage to the transistors that make up the IC that makes up the SSD. The damage occurs because of the tiny breakages that occur in the semiconductor layers of the transistor, which over many P/E cycles cause bitwise errors. Un-bane-ing To counteract these issues, manufacturers usually provide some buffer flash storage in their devices which replace the worn-out storage. From the user’s end, de-duping 4 the data or using compressed data is also effective. De-duping or de-duplication refers to the minimization of duplicated versions of data and is a data reduction technique. RAM—a Solid State Storage device A different type of solid state storage device can be the RAM SSS, which doesn’t have such a write/erase limitation. This is a type of volatile memory, which uses DRAM(Dynamic RAM) or SRAM (Static RAM) whips and thus the lose stored data upon removal of power. They do, however, allow the data to be copied onto a non-volatile memory storage. They generally use a battery along with the chips to allow for storage of data for some time even after main power source is turned off. This is utilized mostly in case of power cuts that the user did not expect. In the end, there are quite a few advantages to using Solid State Storage devices, such as their high speed or operation, low power consumption or noise-less functioning. On the other hand, such devices--especially when integrated as the main drive (SSD) in computers causes increase in overall cost of the machine—due to SSSs being more expensive than their mechanical counterparts, not to mention the durability issues, due to damage caused by program/erase cycles. However, as demand for Solid State Storage devices increases, the costs are surely to decrease, as they did with HDDs. To conclude: solid state devices are here to stay and it’s good that you know about them now. Bibliography and Further Reading https://searchstorage.techtarget.com/definition/SNIA-Solid-State-Storage-Initiative-SSSI https://searchdatacenter.techtarget.com/definition/PCI-Express https://www.storagereview.com/ssd_vs_hdd https://www.computerweekly.com/podcast/Enterprise-MLC-eMLC-and-solid-state-storage-for-the-enterprise https://www.dell.com/support/article/in/en/indhs1/sln156899/hard-drive-why-do-solid-state-devices-ssd-wear-out?lang=en http://www.versiondaily.com/ssd-advantages-disadvantages-solid-state-drive/ Written by Ruchi Pendse. AICVS had it's third session conducted by Mayur Bhangale on 1st September, 2018. The session was attended by 90 students. The main agenda of the session was to keep the topic at hand as realistic as possible so that the audience could get a clearer image as to where the world had progressed in machine learning, what could be done in the next two years and how the budding enthusiasts among us could contribute to the field.  Our speaker, Mayur Bhangale The session began with Mayur Bhangale explaining that although one could theoretically prove that a certain model, if implemented in a certain way would definitely work, we have to understand that since we’re working on a much smaller scale, what we prove on paper might not give us realistic outcomes every time. He gave the example of the concept of self-driving cars which has been in the talks for a few years now. However due the lack of data it has still not been implemented yet. Our other problem is that fact that we don’t have computers powerful enough to run the data (say we’re able to obtain it) required to train the vehicle model to allow it to learn to drive itself. In order to understand how we could make our theories more realistic and result oriented, we have to start with the basics. So, he started with what “Machine learning” really is. He explained that the broad definition of a topic as vast as Machine Learning can be summarized as “the extraction of patterns found for a given data, for which algorithms are written that dictate the class of patterns and predict the outputs, the result of which is a collection of patterns which forms our model.” Some of the common examples of where ML could be employed are, including detection of cancerous cells, email filtering, etc.  Machine Learning Classification Machine learning tasks help understand what kind of model it employs to obtain results from a given data set. They are classified on the basis of whether the learning (making predictions and verifying them against a discriminator) occurs with a signal or feedback being given to the system. The types of learning which an ML model may use are: Supervised learning: A test data set is provided to the algorithm(s) for it to understand patterns found in the actual data set. Thus, examples of inputs and desired outputs are given to the algorithm which should result in it mapping real (non-test) inputs to desired outputs. Supervised learning could be further divided into: 1. Classification: A very binary way of looking at input data, which is divided into classes, where the algorithm assigns the data into two or more labels. The input data must be discrete and thus the output can be accurately obtained. Because the input data classes are known beforehand, this is usually used with a supervised learning model. An example is: spam filtering. 2. Regression: A regression-based model is one where input data is continuous i.e. non-discrete. For example, this model will be used for audio input. Due to the non-discrete form of input, the output always contains an error percentage, which is given in the same units as the result. Hence, regression model will never result in an accurate prediction, because continuous data will never result in 100% accurate results after operation. Unsupervised learning: No test data set is given to the algorithm and it must find its own understanding of mapping input to a desired output. Thus, in unsupervised learning, the algorithm must find all patterns in the data by itself. Unsupervised could be further divided into: 1. Clustering : It is the task of dividing the population or data points into a number of groups such that data points in the same groups are more similar to other data points in the same group and dissimilar to the data points in other groups. It is basically a collection of objects on the basis of similarity and dissimilarity between them. 2. Dimensionality Reduction: It is the process of reducing the number of random variables under consideration, by obtaining a set of principal variables. It can be divided into feature selection and feature extraction. Reinforcement learning: The algorithm is trained to differentiate between desired and undesired output using rewards and punishments as feedback. This form of learning is used in a dynamic environment such as driving a vehicle or playing a game. Reinforcement learning could be further divided as Policy Optimization and Value optimization.  Automatic Feature Extraction using Neural Networks Any machine learning model can be said to fall into any of these three classifications. In deciding which classification an ML model fits into, you would look into the features of your training set. Deciding which features holds more weight will greatly influence the result obtained. This can be decided by the human training the model or by a Neural Network using deep Learning. Deep Learning uses data representations to obtain a result instead of the task-specific algorithms used by ML. Feature extraction with Neural Networks can be an expensive task which increases output but at a significant increase in cost and power. To make multiple decisions or choose multiple features, the Neural Network can have multiple hidden layers. The number of hidden layers is completely up to you. Mayur then talked about CNN’s (Convolutional Neural Networks) and how they are used in Computer Vision. The image is converted into a single column matrix which is multiplied with a weighted matrix to get a result matrix which can then be used to extract certain important features from the image. He then briefly touched on Semantic Segmentation, Image Segmentation, Classification, Localization and Object Detection in Images and talked about their real-world applications.  Architecture of CNN He then talked about NLP (Natural Language Processing) using RNN’s (Recurrent Neural Networks). During text recognition, context is very important and so the model needs to remember the last few words in the text and then only will it be able to infer meaning of the current word. He also talked about some problems this field is facing like catastrophic forgetting, which is the tendency of an neural network to forget previously learned information upon learning new information. RNN’s are used in NLP, Speech recognition and Stock MArket analysis. Mayur then showed us a model which using our input to build a drum kit and build a band that played music. He trained the model on Backstreet Boys music from which it learnt patterns in their music and was able to create its own music from the sound of Mayur tapping on his keyboard.  Knowledge Areas for getting started in ML He then talked about the three ways to get started in Machine learning and referred to the diagram shown above. He said that in learning ML, just the Math Way or the Tools Way or the Hacking Skills Way will not help you truly understand Machine Learning. ML requires good software engineering skills and an ability to understand the Math behind it sufficiently enough to understand what you are doing. Although machine learning has been transformative in some fields, effective machine learning is difficult and many machine-learning programs often fail to deliver the expected value. Reasons for this are numerous: lack of (suitable) data, lack of access to the data, data bias, privacy problems, badly chosen tasks and algorithms, wrong tools and people, lack of resources, and evaluation problems. After the session, the students played a small quiz on Kahoot! which was organised by the AICVS club. The quiz was called YOLO: You Only Learn Once and was a fun little quiz at the end of which 3 students were declared winners. Written by Anuya Joshi, Michelle Davies and Ruchi Pendse. |


